
デザイン演習Ⅲ・Ⅳ
[二年次]arduino等に触れ、IoTについて
[二年次]arduino等に触れ、IoTについて

[二年次]会計的な部分を学び、ビジネスモデルを考える

[一年次]3Dプリンターやレーザーカッター等の機器を用い作成する

[三・四年次]ゼミ

個人的に作成したもの
- import pandas as pd # データ分析に用いるライブラリ
- import matplotlib.pyplot as plt # グラフ表示に用いるライブラリ
- pd.set_option('display.unicode.east_asian_width', True) # 表示のずれを少し緩和
- plt.rcParams['font.family'] = 'IPAexGothic' # グラフ表示におけるフォントの指定
- plt.rcParams['font.size']=4 # グラフに表示される文字のサイズ指定
- data_path = "data.csv" # データを読み込む
- df_data = pd.read_csv(data_path, encoding="utf-8-sig")
- print(df_data.columns) # 項目一覧
- print(df_data["家賃"].describe())
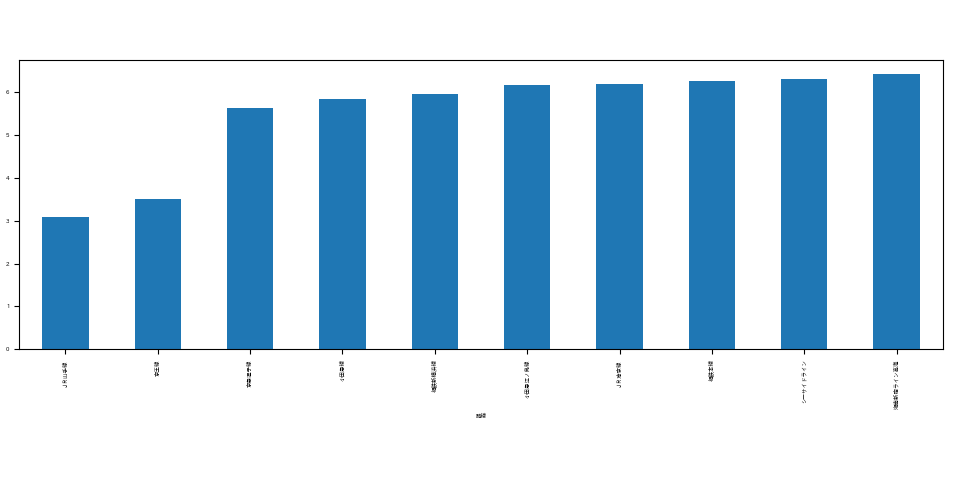
- print(df_data.groupby("路線").mean().loc[:,"家賃"].sort_values()[:10]) # 平均家賃の低い路線トップテンを表示
- df_data.groupby("路線").mean().loc[:,"家賃"].sort_values()[:10].plot.bar(figsize = (10, 8)) # グラフサイズの指定(大きくすると文字が小さくな
- plt.subplots_adjust(left=0.02, right=0.98,bottom=0.3)
- plt.show()
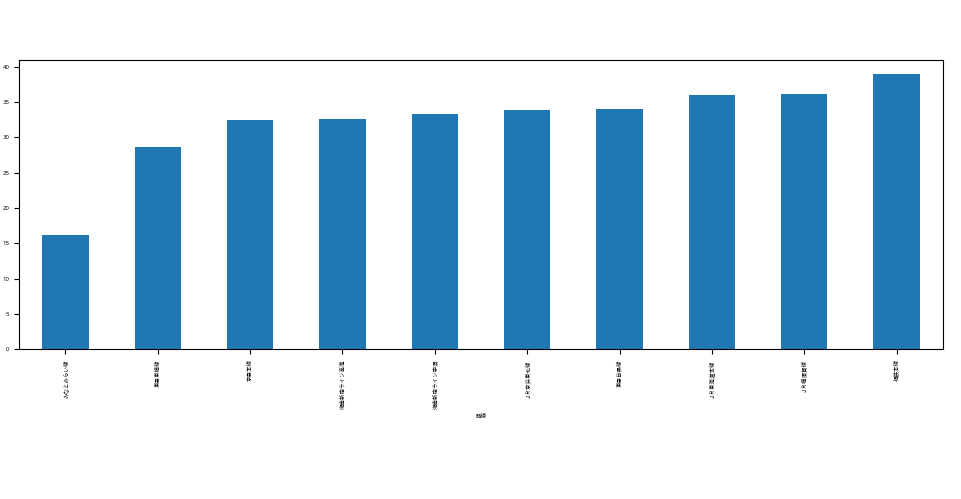
- print(df_data.groupby("路線").mean().loc[:,"合計時間"].sort_values()[:10]) # 平均合計時間の短い路線トップテンを表示
- df_data.groupby("路線").mean().loc[:,"合計時間"].sort_values()[:10].plot.bar(figsize = (10, 8)) # グラフサイズの指定(大きくすると文字が小さくな
- plt.subplots_adjust(left=0.02, right=0.98,bottom=0.3)
- plt.show()
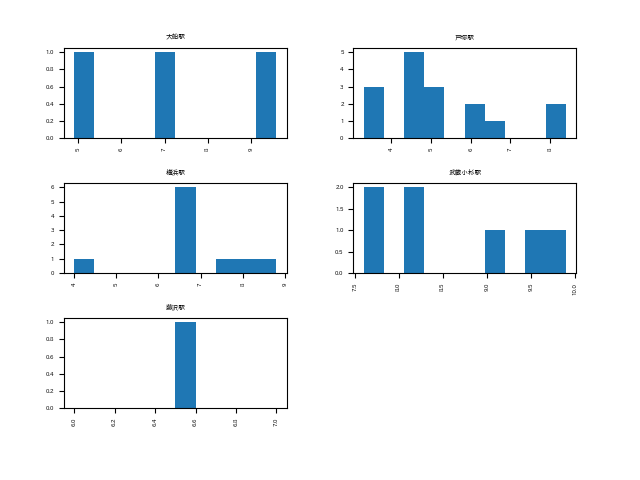
- mask = (df_data["路線"] == "湘南新宿ライン高海") # 湘南新宿ライン高梅に路線を限定
- print(df_data[mask])
- axes = df_data[mask].loc[:, "家賃"].hist(by=df_data[mask].loc[:, "駅"]) # 駅と家賃のヒストグラム
- plt.show()

follow me!